Cloud computing trends 2026: 5 shifts defining the future of AI
For software engineers and data scientists, the cloud is no longer just a storage locker or a virtual server farm; it is the operating system of artificial intelligence. As we look toward 2026, the convergence of high-performance computing (HPC) and generative AI is forcing a radical redesign of cloud architecture.
The era of “lift and shift” is over. We are now entering a phase of cloud native AI optimization, where infrastructure is defined by the specific needs of large language models (LLMs) and real time inference. For teams building models in PyTorch or TensorFlow, understanding these shifts isn’t just about staying current; it’s about survival.
In this article, we’ll analyze the critical cloud computing trends projected to dominate the landscape in 2026. You will learn:
- How specialized silicon is replacing general purpose computers for training runs.
- The evolution of serverless architectures for heavy GPU workloads.
- Why FinOps is becoming a mandatory skill for AI engineering teams.
- The rise of the “sovereign cloud” for regulatory compliance.
1. The rise of AI native infrastructure and specialized silicon
By 2026, the standard CPU centric cloud instance will be insufficient for the majority of enterprise AI workloads. The demand for faster model training and lower inference latency is driving cloud providers to move beyond generic hardware.
We are seeing a massive pivot toward AI native infrastructure. This involves data centers designed from the ground up to handle the thermal and power demands of massive clusters, alongside a diversification of the silicon layer.
Beyond the GPU monopoly
While NVIDIA GPUs remain the gold standard, 2026 will see the maturation of alternative application specific integrated circuits (ASICs). Cloud providers are aggressively deploying proprietary chips optimized for specific parts of the ML lifecycle:
- Training Chips: Processors designed solely for the matrix multiplication intensity of backpropagation.
- Inference Chips: Low power, high efficiency silicon designed to run trained models at the edge or in the cloud with minimal latency.
Why this matters for developers:
You will need to become comfortable optimizing your code for different hardware backends. Tools that abstract this complexity allowing you to write in Python/PyTorch and deploy to a Google TPU, AWS Trainium, or a specialized inference chip without refactoring will become essential parts of your CI/CD pipeline.
2. Serverless GPU and Inference as a Service
Serverless computing has traditionally been limited to CPU bound, event driven functions. However, the friction of provisioning and managing GPU clusters for sporadic inference workloads is a major bottleneck for engineering teams.
In 2026, we expect Serverless GPU to become the default deployment model for inference. This paradigm shift allows developers to deploy models as APIs without managing the underlying instances. The cloud provider handles the “cold start” of the GPU and scales the resources down to zero when no requests are coming in.
The benefits of abstraction
- Cost Efficiency: You stop paying for idle GPU time, which is traditionally the highest cost center in AI deployment.
- Scalability: The platform automatically handles spikes in user traffic, ensuring high availability without manual autoscaling configuration.
- Developer Experience: Teams can focus on model weights and API logic rather than Kubernetes node pools or driver compatibility.
This trend effectively democratizes access to high performance computing, allowing smaller teams to deploy state of the art models without a dedicated DevOps engineer managing the infrastructure.
3. FinOps 2.0: Automated cost optimization for AI
As AI budgets balloon, finance departments are scrutinizing cloud bills with unprecedented intensity. The days of spinning up a cluster and forgetting to shut it down are ending. By 2026, FinOps (Financial Operations) will evolve from a reporting function into an automated engineering discipline.
We anticipate the integration of AI driven cost optimization directly into the cloud control plane. These tools will not just report on spend; they will actively manage it.
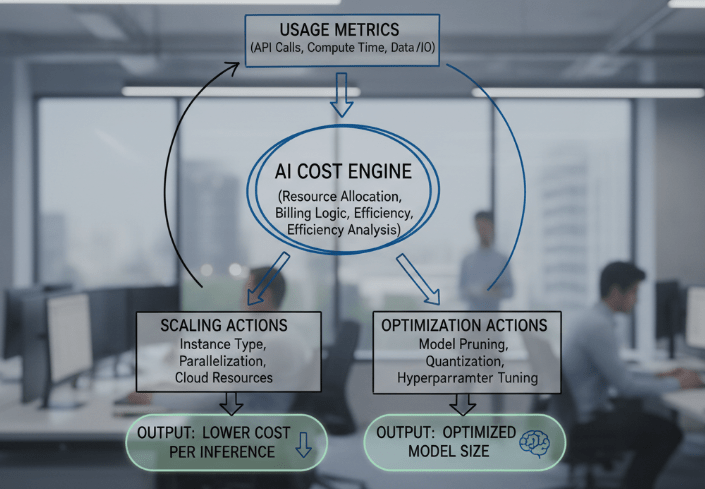
What automated FinOps looks like
- Predictive Scaling: Using historical usage data to pre provision spot instances for training runs at the lowest possible market price.
- Model Right Sizing: Automated recommendations that analyze inference patterns and suggest switching to smaller, quantized models or less powerful instance types to maintain performance while cutting costs.
- Waste Identification: Real time termination of zombie processes and unattached storage volumes associated with abandoned experiments.
For data scientists, this means “cost per inference” will become a key performance metric alongside accuracy and F1 scores.
4. The distributed cloud and Edge AI
Centralized cloud regions (like us east 1) are becoming bottlenecks for real-time applications that require near-store decision making. Whether it’s autonomous logistics or healthcare monitoring, the latency introduced by round tripping data to a central server is unacceptable.
The trend for 2026 is the distributed cloud, where compute power is pushed closer to the data source. This is critical for Edge AI, where models run on gateways or on-premise servers but are managed via a centralized cloud interface.
Key architectural shifts
- Federated Learning: This allows models to be trained across multiple decentralized edge devices holding local data samples, without exchanging them. This addresses privacy concerns and bandwidth constraints.
- 5G Integration: The rollout of private 5G networks in industrial settings enables the cloud to extend seamlessly to the factory floor, allowing for real-time video analytics and robotic control.
This shift requires developers to build “location aware” applications. You will need architect systems where the model can run comfortably on a constrained edge device while syncing critical insights back to the core cloud for long term storage and analysis.
5. Multi cloud abstraction and data sovereignty
With the implementation of strict data regulations like the EU AI Act and GDPR, data sovereignty on the concept that data is subject to the laws of the nation within which it is collected is a top priority.
Enterprises can no longer rely on a single cloud provider for global operations. By 2026, we will see robust multi cloud abstraction layers. These platforms (often utilizing Kubernetes and service meshes) allow teams to define policies that automatically route data and workloads to specific geographic regions based on compliance requirements.
The “Supercloud” concept
This abstraction layer creates a “Supercloud” above the hyperscalers (AWS, Azure, Google Cloud). It provides a unified API for storage, computing, and networking.
- Vendor Neutrality: Reduces the risk of vendor locking in, allowing you to move workloads to whichever provider offers the best performance or price for a specific task.
- Resilience: If one provider experiences an outage in a specific region, the abstraction layer can fail to a different provider automatically.
For the developer, this means learning to write infrastructure as code (IaC) that is agnostic to the underlying provider, focusing on the application logic rather than the proprietary services of a single vendor.
Preparing your stack for the next generation
The cloud landscape of 2026 offers immense power, but it demands a higher level of architectural discipline. The successful AI engineer will not just be a model builder; they will be a systems thinker who understands how to leverage specialized silicon, manage costs through automation, and deploy across a distributed environment.
To prepare for these shifts, we recommend the following next steps:
- Audit your current training infrastructure: Are you using generic instances where specialized chips could offer better price/performance?
- Explore serverless inference: Test deploying a smaller model using a serverless GPU offering to understand the latency and cost implications.
- Implement tagging strategies: Ensure every resource in your cloud environment is tagged by project and team to prepare for advanced FinOps automation.
The cloud is evolving to meet the needs of AI. By aligning your skills and tech stack with these trends, you position your projects for scalability, efficiency, and long-term success.

Leave a comment